React Native와 NestJS를 활용한 Google Cloud Speech-to-Text 구현하기
React Native와 NestJS를 활용한 Google Cloud Speech-to-Text 구현하기
오늘은 모바일 애플리케이션에서 음성 인식 기능을 구현하는 방법에 대해 알아보겠습니다. 특히 React Native로 구현된 프론트엔드와 NestJS로 구현된 백엔드를 통해 Google Cloud Speech-to-Text API를 연동하는 방법을 자세히 설명하겠습니다.
개요
이 글에서는 다음과 같은 내용을 다룹니다:
- Google Cloud Speech-to-Text API 설정
- NestJS 백엔드 구현
- React Native 프론트엔드 구현
- 비용 정보 및 무료 티어 활용 방법
1. Google Cloud Speech-to-Text API 설정
1.1 Google Cloud SDK 설치
맥OS에서는 Homebrew를 통해 Google Cloud SDK를 설치합니다:
brew install --cask google-cloud-sdk
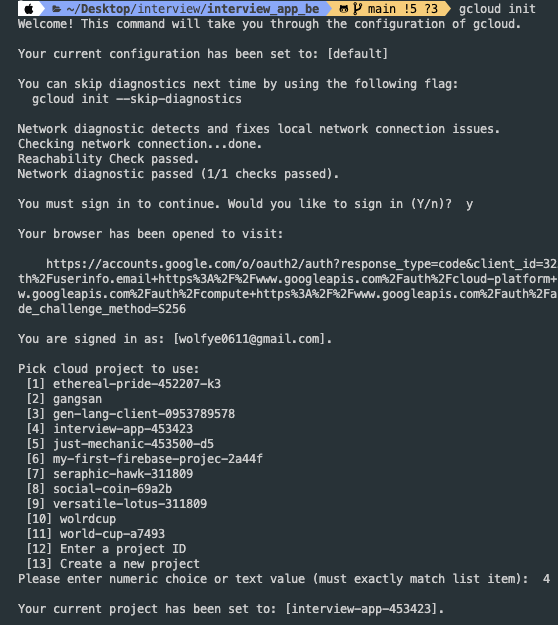
설치 후 초기화를 진행합니다:
gcloud init
1.2 서비스 계정 생성 및 인증 키 설정
- Google Cloud Console에 로그인 후 IAM & Admin > Service Accounts로 이동
- 새 서비스 계정 생성 및 필요한 권한 부여
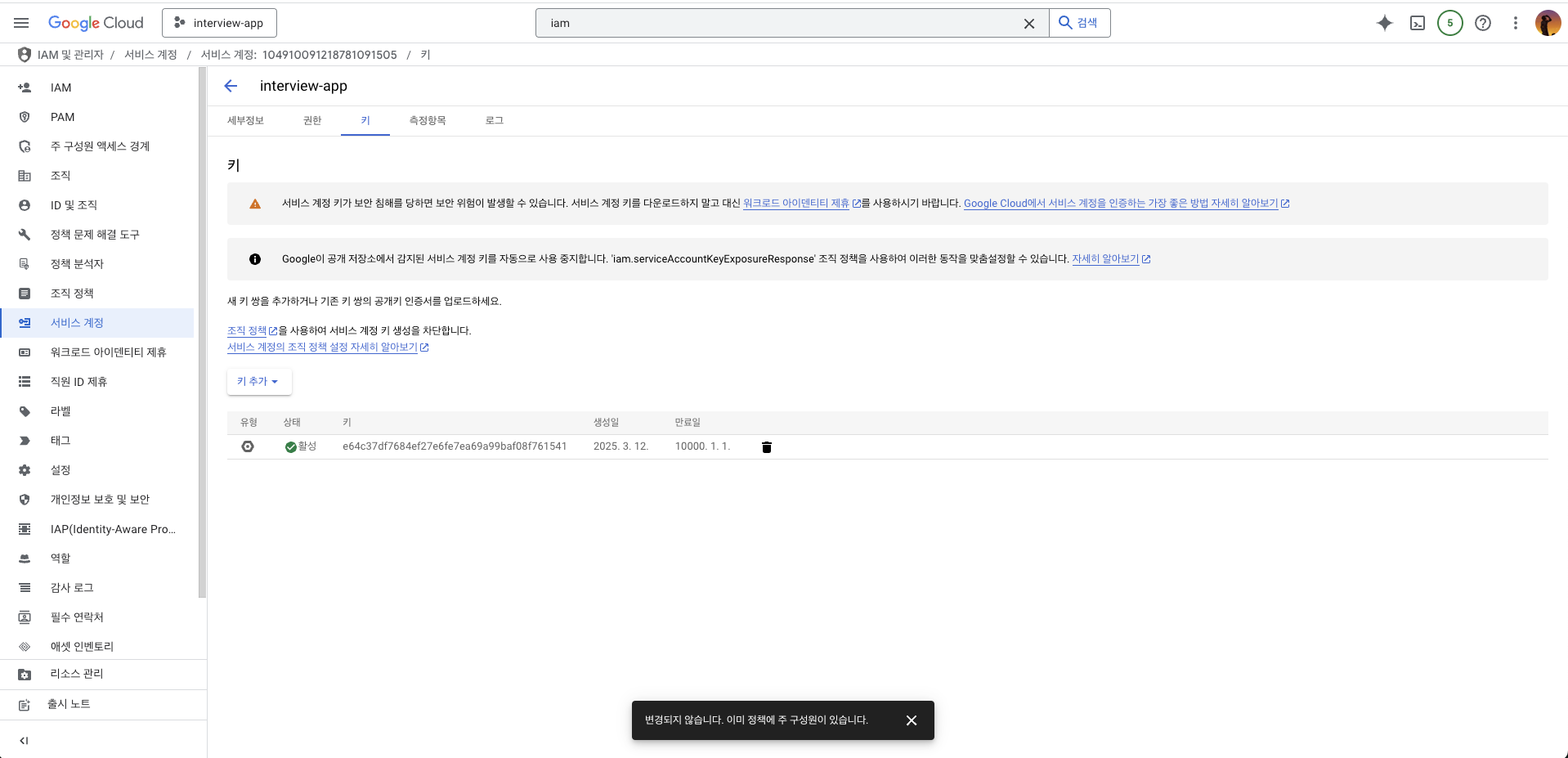
- JSON 형식의 키 생성 및 다운로드
- 서비스 계정 인증 활성화:
gcloud auth activate-service-account --key-file=google-credentials.json
1.3 환경 변수 설정
서비스 계정 키를 사용하기 위해 환경 변수를 설정해야 합니다:
방법 1: 터미널에서 설정
export GOOGLE_APPLICATION_CREDENTIALS=~/path/to/google-credentials.json
// 저의 경우
export GOOGLE_APPLICATION_CREDENTIALS=~/Desktop/interview/interview_app_be/google-credentials.json
방법 2: .env 파일에 추가
GOOGLE_APPLICATION_CREDENTIALS=google-credentials.json
그리고 NestJS 프로젝트의 main.ts에서 dotenv 설정:
import * as dotenv from 'dotenv';
dotenv.config();
2. NestJS 백엔드 구현
2.1 필요한 패키지 설치
추후에 ec2로 배포한다면 ec2에도 ffmpeg를 설치해줘야 합니다.
npm install --save @google-cloud/speech
npm install fluent-ffmpeg
brew install ffmpeg # macOS용 ffmpeg 설치
2.2 Audio 서비스 구현
NestJS에서 음성 인식을 처리하는 서비스를 구현합니다:
import { Injectable } from '@nestjs/common';
import { InjectRepository } from '@nestjs/typeorm';
import { Audio } from './entities/audio.entity';
import { Repository } from 'typeorm';
import {
UploadSpeechFileInput,
UploadSpeechFileOutput,
} from './dtos/upload-speech-file.dto';
import { promises as fsPromises } from 'fs';
import { join } from 'path';
import speech, { protos } from '@google-cloud/speech';
import * as ffmpeg from 'fluent-ffmpeg';
@Injectable()
export class AudioService {
private readonly client = new speech.SpeechClient();
constructor(
@InjectRepository(Audio)
private audioRepository: Repository<Audio>,
) {}
// MP3 파일을 FLAC 형식으로 변환
private async convertMp3ToFlac(
inputPath: string,
outputPath: string,
): Promise<void> {
return new Promise((resolve, reject) => {
ffmpeg(inputPath)
.output(outputPath)
.audioCodec('flac')
.audioChannels(1)
.on('end', () => {
console.log(`파일 변환 완료: ${outputPath}`);
resolve();
})
.on('error', (err) => {
console.error('파일 변환 실패:', err);
reject(err);
})
.run();
});
}
// 음성 파일 저장 및 처리
async saveFile({
file,
}: UploadSpeechFileInput): Promise<UploadSpeechFileOutput> {
const base64Data = file.split(';base64,').pop();
if (!base64Data) {
throw new Error('잘못된 파일 형식입니다.');
}
// 파일 저장
const fileName = `${Date.now()}.mp3`;
const directoryPath = join(__dirname, '..', 'uploads');
await fsPromises.mkdir(directoryPath, { recursive: true });
const filePath = join(directoryPath, fileName);
const buffer = Buffer.from(base64Data, 'base64');
try {
await fsPromises.writeFile(filePath, buffer);
console.log('파일 저장 성공:', filePath);
} catch (err) {
console.error('파일 저장 실패:', err);
throw new Error('파일 저장 실패');
}
// MP3를 FLAC로 변환
const outputFilePath = join(directoryPath, `${Date.now()}.flac`);
await this.convertMp3ToFlac(filePath, outputFilePath);
// 변환된 FLAC 파일을 사용하여 텍스트 변환
const transcribedText = await this.transcribeAudio(outputFilePath);
// 결과 저장
const audio = this.audioRepository.create({
filePath: outputFilePath,
transcribedText,
});
await this.audioRepository.save(audio);
return { ok: true, feedback: '업로드 성공' };
}
// Google Cloud Speech-to-Text API를 사용한 음성 인식
private async transcribeAudio(audioPath: string): Promise<string> {
const audio = {
content: await fsPromises.readFile(audioPath, 'base64'),
};
const request = {
audio,
config: {
encoding:
protos.google.cloud.speech.v1.RecognitionConfig.AudioEncoding.FLAC,
languageCode: 'ko', // 한국어 설정
},
};
try {
const [response] = await this.client.recognize(request);
const transcription = response.results
.map((result) => result.alternatives[0].transcript)
.join('\n');
return transcription;
} catch (error) {
console.error('음성 인식 실패:', error);
throw new Error('음성 인식 실패');
}
}
}
2.3 주요 구현 내용 설명
- 파일 처리:
- Base64로 인코딩된 음성 파일을 서버에 저장
- MP3 파일을 Google Cloud가 최적으로 처리할 수 있는 FLAC 형식으로 변환
- 음성 인식:
- Google Cloud Speech-to-Text API를 사용하여 변환된 FLAC 파일에서 텍스트 추출
- 한국어(ko) 언어 코드 설정
- 결과 저장:
- 변환된 텍스트를 데이터베이스에 저장

3. React Native 프론트엔드 구현
3.1 음성 녹음 및 업로드 구현
React Native에서는 Expo의 Audio API를 사용하여 음성을 녹음하고, 녹음된 파일을 Base64로 인코딩하여 서버로 전송합니다:
const uploadAudio = async () => {
if (!recordedUri) {
Alert.alert('먼저 녹음하세요!');
return;
}
const fileInfo = await FileSystem.getInfoAsync(recordedUri);
if (!fileInfo.exists) {
Alert.alert('파일이 존재하지 않습니다.');
return;
}
try {
// 파일을 Base64로 읽어오기
const base64 = await FileSystem.readAsStringAsync(recordedUri, {
encoding: FileSystem.EncodingType.Base64,
});
// GraphQL로 파일 전송
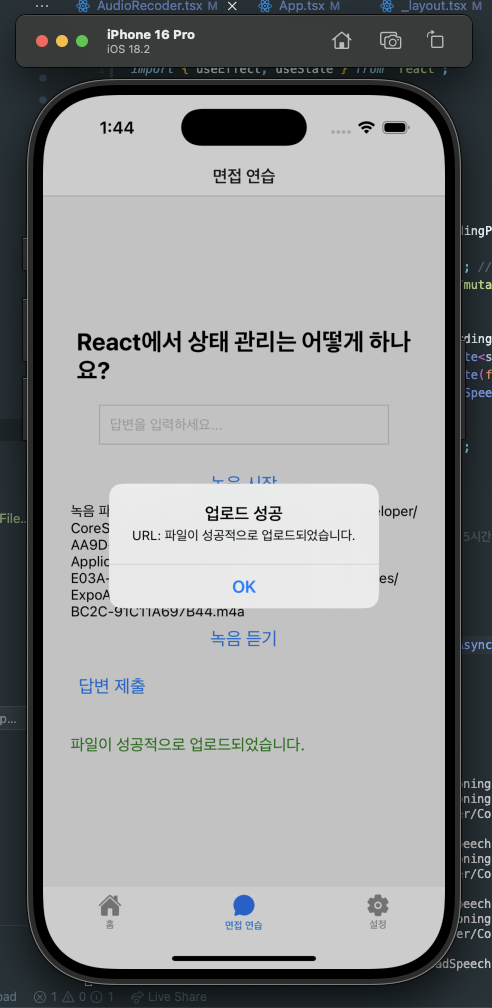
const result = await uploadSpeechFile(base64);
console.log('업로드 성공:', result);
Alert.alert('업로드 성공', `URL: ${result?.feedback}`);
} catch (error) {
console.error('업로드 실패:', error);
Alert.alert('업로드 실패', '서버 오류');
}
};
3.2 기능 구현 시 주의사항
- 파일 크기: 음성 파일은 크기가 클 수 있으므로, 네트워크 상태를 고려하여 사용자에게 적절한 피드백 제공
- 권한 처리: 마이크 접근 권한을 사용자에게 요청하고 거부 시 적절한 안내 제공
- 파일 형식: 모바일 기기에서 녹음된 파일이 서버에서 지원하는 형식인지 확인
4. Google Cloud Speech-to-Text API 비용 정보
4.1 무료 티어 활용하기
Google Cloud 신규 사용자는 $300 크레딧을 받아 3개월 동안 무료로 서비스를 사용할 수 있습니다. 이는 개발 및 테스트 단계에서 충분히 활용할 수 있는 금액입니다.
4.2 Speech-to-Text V2 API 요금
표준 인식 모델:
- 0분~500,000분: US$0.016/분
- 500,000분~1,000,000분: US$0.01/분
- 1,000,000분~2,000,000분: US$0.008/분
- 2,000,000분 이상: US$0.004/분
데이터 로깅 활성화 시:
- 0분~500,000분: US$0.012/분
- 500,000분~1,000,000분: US$0.0075/분
- 1,000,000분~2,000,000분: US$0.006/분
- 2,000,000분 이상: US$0.003/분
4.3 Speech-to-Text V1 API 요금
표준 모델:
- 0분~60분: 무료
- 60분 이상(데이터 로깅 포함): US$0.016/분
- 60분 이상(데이터 로깅 없음): US$0.024/분
의료 모델:
- 0분~60분: 무료
- 60분 이상: US$0.078/분
결론
Google Cloud Speech-to-Text API를 React Native와 NestJS로 연동하는 방법을 살펴보았습니다. 실제 구현 시에는 사용자 경험을 최우선으로 하되, 비용 효율성도 고려해야 합니다.
특히 무료 티어를 활용하여 개발 및 테스트를 하고, 실제 프로덕션 환경에서는 최적화된 설정을 통해 비용을 절감하는 것이 중요합니다.
이 글이 음성 인식 기능을 구현하는 데 도움이 되었기를 바랍니다. 궁금한 점이나 추가적인 정보가 필요하시면 댓글로 남겨주세요.